Diabetes is a chronic health condition that affects a huge number of the population throughout the world.
Diabetes is a health disorder that results in an increase in blood glucose level.
In this project, we will implement an Artificial Neural Network (ANN) for diabetes predictions in order to predict the onset of diabetes based on a set of diagnostic measures.
Model
Among the different machine learning (ML) models used for diabetes prediction such as support vector machines (SVM), decision trees (DT) or random forest (RF), we will focus on artificial neural networks (ANN).
An artificial neural network is a model inspired by the structure of neural networks in the brain.
ANN consist of a large number of basic units called neurons that are connected to each other. A neural network can be described as a directed graph whose nodes correspond to neurons and edges to links between them. Each neuron receives as inputs a weighted sum of the outputs of the neurons connected to its incomming edges. ANN uses an activation functions to transform the sum of weighted inputs given at a node into activation of that node.
Data
We will use the publicly available Pima Indians Diabetes dataset. It describes patient medical record data for 768 women patients and whether they had an onset of diabetes within five years. It is binary classification problem and all the input variables that describe each patient are numerical. The variables can be summarized as follows:
- Pregnant: number of times pregnant.
- Glucose: plasma glucose concentration a two hours in an oral glucose tolerance test.
- Pressure: diastolic blood pressure.
- Triceps: Triceps skin fold thickness
- Insulin: 2-h serum insulin.
- Mass: body mass index.
- Pedigree: diabetes pedigree function.
- Age: age
- Diabetes: class variable (0 or 1).
Implementation
The following network architecture will be implemented:
- Input layer.
- Layer dense with 20 nodes.
- Layer dense with 10 nodes.
- Output layer.
In order to implement it, we will use the python API Keras, built on top of TensorFlow. The source code can be found in GitHub-ANN-diabetes.
Data Pre-Processing
We firtly removed instances with missing values. They correspond to patients with glucose, blood pressure, skin thickness, insulin or BMI set to zero.
Results
import numpy as np
model_1 = tf.keras.models.Sequential()
model_1.add(tf.keras.layers.Dense(units=20, activation='relu',input_shape = [8]))
model_1.add(tf.keras.layers.Dense(units=10, activation='relu'))
model_1.add(tf.keras.layers.Dense(units=1, activation='relu'))
model_1.summary()
model_1.compile(
loss='binary_crossentropy',
optimizer= "adam",
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')]
)
history = model_1.fit(X_train, y_train, epochs=50,batch_size = 5,validation_split = 0.2)
When evaluating our ANN we have obtained an accuracy of 0.71.
y_pred = model_1.predict(X_test)
test_loss, test_acc = model_1.evaluate(X_test, y_test)
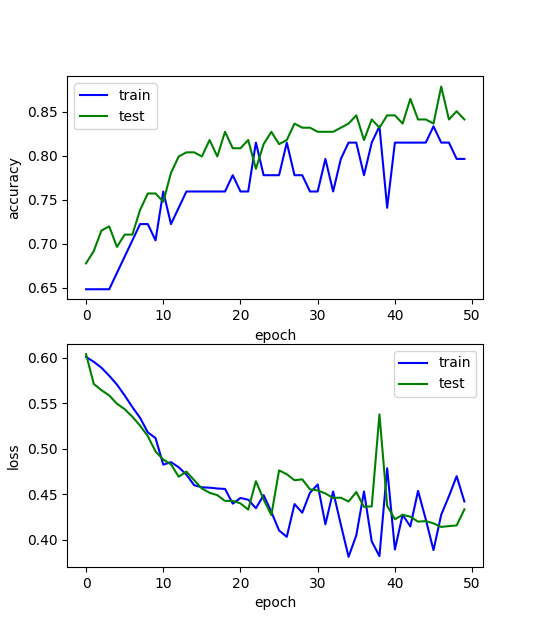
We also show the training and test accuracy and loss during the training phase.
To be continued…
We notice that the final model accuracy could be improved. A quickly internet inspection shows that higher accuracies have been obtained.
In a future work, we will dig deeper into the network architecture and hyperparameters, and also test different approaches.